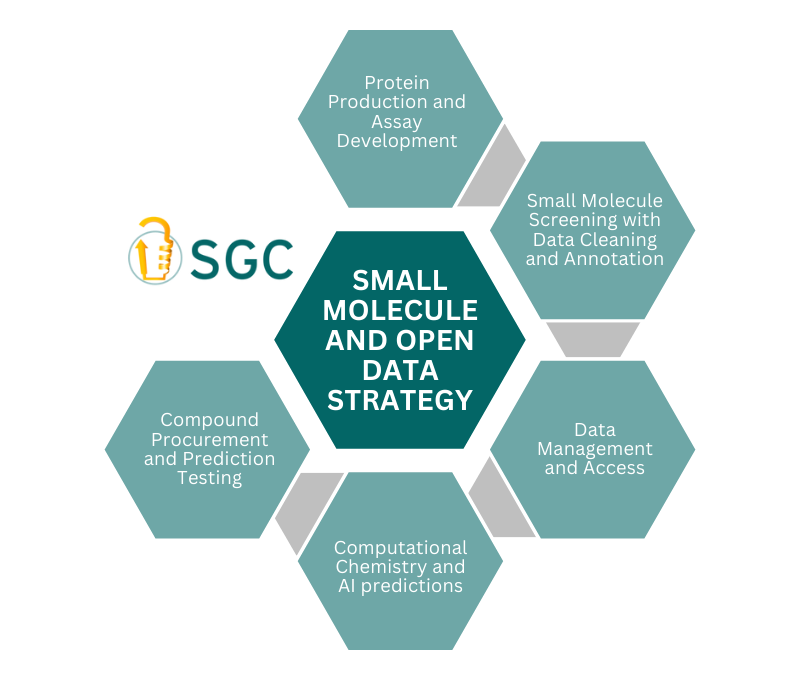
Our Open Data Strategy
SGC’s open data strategy is an ambitious and robust plan to spearhead the era of computational science in drug discovery. Using advanced technologies such as Affinity Selection Mass Spectrometry (AS-MS) and DNA-Encoded Libraries (DEL), along with innovative computational platforms like AIRCHECK, we are committed to data excellence and collaboration. This strategic approach positions SGC at the forefront of significant advancements in computational drug discovery and machine learning (ML) and artificial intelligence (AI) applications but also aligns with the Target 2035 initiative. By 2030, SGC and Target 2035 will have identified experimentally verified hits for thousand of human proteins and will push forward the development of open-access algorithms capable of predicting hits for proteins with no experimental data.
-
Affinity Selection Mass Spectrometry (AS-MS)
-
DNA-Encoded Libraries (DEL)
-
Benchmarking Purely Computational Approaches
Key Technologies
Affinity Selection Mass Spectrometry (AS-MS):
Our AS-MS platform is designed to generate large-scale protein-ligand interaction data. By screening thousands of different proteins, we will create an open dataset featuring over 50 million protein-ligand interactions. This initiative is supported by a 500,000-compound library, developed in collaboration with our Pharma partners.
DNA-Encoded Libraries (DEL):
We are leveraging the power of DNA-encoded libraries combined with machine learning. Key aspects include:
Public Domain Data: DEL screens for thousands of proteins will be made publicly available, allowing data scientists and ML/AI researchers to predict hits from commercial libraries.
Unprecedented Scale: We aim to generate a dataset exceeding 1 trillion data points, driving innovation and discovery.
Benchmarking Purely Computational Approaches:
We provide logistic and experimental support for the CACHE challenges; an initiative that benchmarks computational methods for small molecule discovery. The biophysics platform at SGC-Toronto acts as the experimental arm of CACHE, rigorously testing the predicted compounds and providing rapid, high-quality characterization of all the predicted hits. Our process involves screening predicted compounds, validating hits using orthogonal methods, and assessing their solubility and aggregation within a 3-month timeline. After this, we return the resulting data to participants for the hit-expansion round of each CACHE Challenge. Learn more about CACHE Challenges.
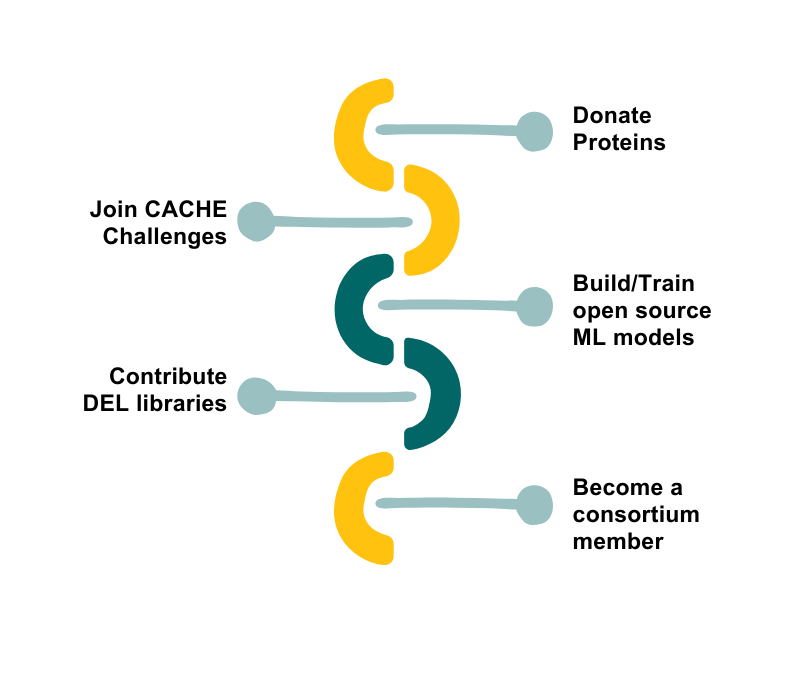
How to participate
Join the SGC’s Open Data Strategy and contribute to our mission to democratize drug discovery and accelerate the development of new therapies.